在版本3.2之前,Redis 列表list使用两种数据结构作为底层实现:
- 压缩列表ziplist
- 双向链表linkedlist
因为双向链表占用的内存比压缩列表要多, 所以当创建新的列表键时, 列表会优先考虑使用压缩列表, 并且在有需要的时候, 才从压缩列表实现转换到双向链表实现。
压缩列表转化成双向链表条件
创建新列表时 redis 默认使用 redis_encoding_ziplist 编码, 当以下任意一个条件被满足时, 列表会被转换成 redis_encoding_linkedlist 编码:
- 试图往列表新添加一个字符串值,且这个字符串的长度超过 server.list_max_ziplist_value (默认值为 64 )。
- ziplist 包含的节点超过 server.list_max_ziplist_entries (默认值为 512 )。
双向链表linkedlist
当压缩列表entry数据超过512、或单个value 长度超过64,底层就会转化成linkedlist编码;
linkedlist是标准的双向链表,Node节点包含prev和next指针,可以进行双向遍历;
还保存了 head 和 tail 两个指针,因此,对链表的表头和表尾进行插入的复杂度都为 (1) —— 这是高效实现 LPUSH 、 RPOP、 RPOPLPUSH 等命令的关键。
linkedlist比较简单,我们重点来分析ziplist。
压缩列表ziplist
压缩列表 ziplist 是为 Redis 节约内存而开发的。
ziplist 是由一系列特殊编码的内存块构成的列表(像内存连续的数组,但每个元素长度不同), 一个 ziplist 可以包含多个节点(entry)。
ziplist 将表中每一项存放在前后连续的地址空间内,每一项因占用的空间不同,而采用变长编码。
当元素个数较少时,Redis 用 ziplist 来存储数据,当元素个数超过某个值时,链表键中会把 ziplist 转化为 linkedlist,字典键中会把 ziplist 转化为 hashtable。
由于内存是连续分配的,所以遍历速度很快。
在3.2之后,ziplist被quicklist替代。但是仍然是zset底层实现之一。
ziplist 是一个特殊的双向链表
特殊之处在于:没有维护双向指针:prev next;而是存储上一个 entry的长度和 当前entry的长度,通过长度推算下一个元素在什么地方。
牺牲读取的性能,获得高效的存储空间,因为(简短字符串的情况)存储指针比存储entry长度 更费内存。这是典型的“时间换空间”。
ziplist使用局限性
字段、值比较小,才会用ziplist。
ziplist存储结构
ziplist使用连续的内存块,每一个节点(entry)都是连续存储的;ziplist 存储分布如下:
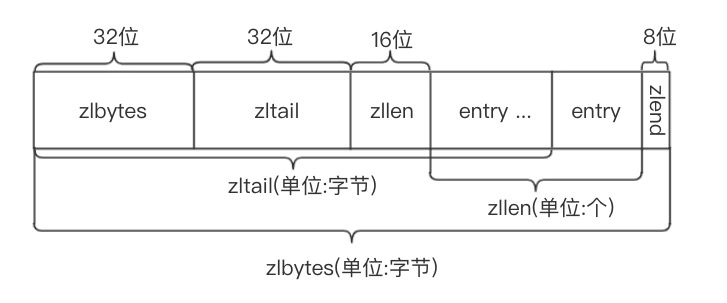
- zlbytes: ziplist的长度(单位: 字节),是一个32位无符号整数
- zltail: ziplist最后一个节点的偏移量,反向遍历ziplist或者pop尾部节点的时候有用。
- zllen: ziplist的节点(entry)个数
- entry: 节点
- zlend: 值为0xFF,用于标记ziplist的结尾
由于每一项、占用的空间可能都不同,只能在添加entry的时候确定,也就是每个entry占用的实际长度只有在节点添加后才确定,因此entry采用变长编码。
普通数组的遍历是根据数组里存储的数据类型 找到下一个元素的,例如int类型的数组访问下一个元素时每次只需要移动一个sizeof(int)就行(实际上开发者只需让指针p+1就行,在这里引入sizeof(int)只是为了说明区别)。
上文说了,ziplist的每个节点的长度是可以不一样的,而我们面对不同长度的节点又不可能直接sizeof(entry),那么它是怎么访问下一个节点呢?
ziplist将一些必要的偏移量信息记录在了每一个节点里,使之能跳到上一个节点或下一个节点。
ziplist节点entry结构
每一个存储节点(entry)都是一个zlentry (zip list entry)。
zlentry的源码定义:
typedef struct zlentry { // 压缩列表节点
unsigned int prevrawlensize, prevrawlen; // prevrawlen是前一个节点的长度,prevrawlensize是指prevrawlen的大小,有1字节和5字节两种
unsigned int lensize, len; // len为当前节点长度 lensize为编码len所需的字节大小
unsigned int headersize; // 当前节点的header大小
unsigned char encoding; // 节点的编码方式
unsigned char *p; // 指向节点的指针
} zlentry;
void zipEntry(unsigned char *p, zlentry *e) { // 根据节点指针返回一个enrty
ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen); // 获取prevlen的值和长度
ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len); // 获取当前节点的编码方式、长度等
e->headersize = e->prevrawlensize + e->lensize; // 头大小
e->p = p;
}每个节点由三部分组成:prevlength、encoding、data
- prevlengh: 记录上一个节点的长度,为了方便反向遍历ziplist
- encoding: 当前节点的编码规则,下文会详细说
- data: 当前节点的值,可以是数字或字符串
为了节省内存,根据上一个节点的长度prevlength 可以将ziplist节点分为两类:
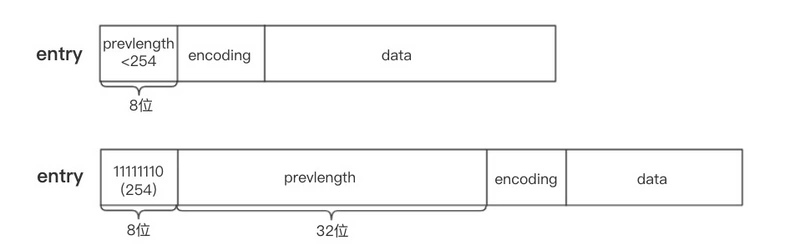
- entry的前8位小于254,则这8位就表示上一个节点的长度
- entry的前8位等于254,则意味着上一个节点的长度无法用8位表示,后面32位才是真实的prevlength。用254 不用255(11111111)作为分界是因为255是zlend的值,它用于判断ziplist是否到达尾部。
如何通过一个节点向前跳转到另一个节点?
用指向当前节点的指针 e , 减去 前一个 entry的长度, 得出的结果就是指向前一个节点的地址 p 。
ziplist连锁更新问题
因为在ziplist中,每个zlentry都存储着前一个节点所占的字节数,而这个数值又是变长编码的。假设存在一个压缩列表,其包含e1、e2、e3、e4.....,e1节点的大小为253字节,那么e2.prevrawlen的大小为1字节,如果此时在e2与e1之间插入了一个新节点e_new,e_new编码后的整体长度(包含e1的长度)为254字节,此时e2.prevrawlen就需要扩充为5字节;如果e2的整体长度变化又引起了e3.prevrawlen的存储长度变化,那么e3也需要扩.......如此递归直到表尾节点或者某一个节点的prevrawlen本身长度可以容纳前一个节点的变化。其中每一次扩充都需要进行空间再分配操作。删除节点亦是如此,只要引起了操作节点之后的节点的prevrawlen的变化,都可能引起连锁更新。
连锁更新在最坏情况下需要进行N次空间再分配,而每次空间再分配的最坏时间复杂度为O(N),因此连锁更新的总体时间复杂度是O(N^2)。
即使涉及连锁更新的时间复杂度这么高,但它能引起的性能问题的概率是极低的:需要列表中存在大量的节点长度接近254的zlentry。
ziplist的主要优点是节省内存,但它上面的查找操作只能按顺序查找(可以是从前往后、也可以从后往前)。
ziplist将数据按照一定规则编码在一块连续的内存区域,目的是节省内存,这种结构并不擅长做修改操作。一旦数据发生改动,就会引发内存realloc,可能导致内存拷贝。
Redis3.2+ list的新实现quickList
Redis中的列表list,在版本3.2之前,列表底层的编码是ziplist和linkedlist实现的,但是在版本3.2之后,重新引入 quicklist,列表的底层都由quicklist实现。
在版本3.2之前,当列表对象中元素的长度比较小或者数量比较少的时候,采用ziplist来存储,当列表对象中元素的长度比较大或者数量比较多的时候,则会转而使用双向列表linkedlist来存储。
这两种存储方式的优缺点
- 双向链表linkedlist便于在表的两端进行push和pop操作,在插入节点上复杂度很低,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
- ziplist存储在一段连续的内存上,所以存储效率很高。但是,它不利于修改操作,插入和删除操作需要频繁的申请和释放内存。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝。
quickList
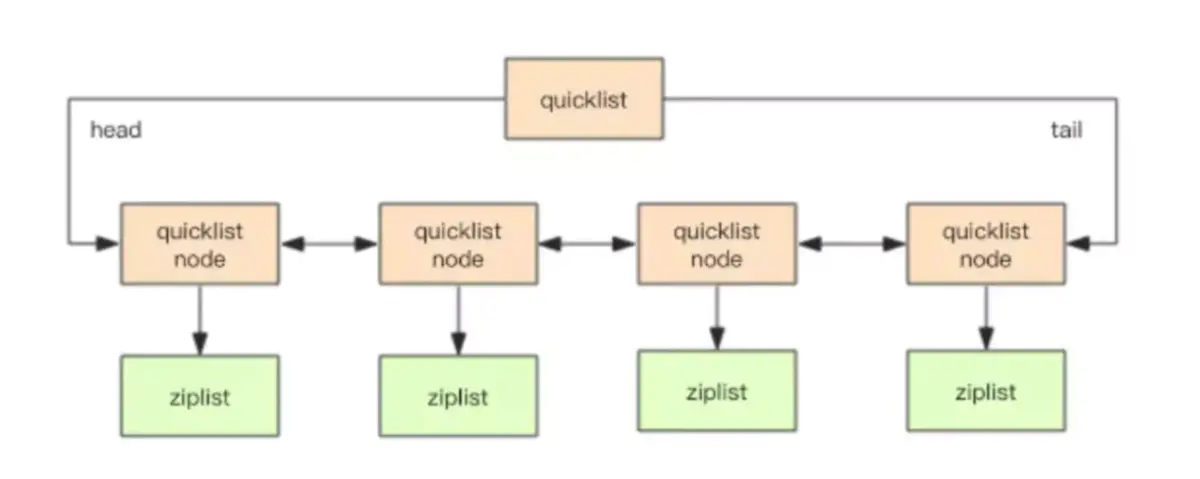
可以认为quickList,是ziplist和linkedlist二者的结合;quickList将二者的优点结合起来。
quickList是一个ziplist组成的双向链表。每个节点使用ziplist来保存数据。
本质上来说,quicklist里面保存着一个一个小的ziplist。结构如下:
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 12 bits, free for future use; pads out the remainder of 32 bits
*/
typedef struct quicklistNode {
struct quicklistNode *prev; //上一个node节点
struct quicklistNode *next; //下一个node
unsigned char *zl; //保存的数据 压缩前ziplist 压缩后压缩的数据
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'.
* 'sz' is byte length of 'compressed' field.
* 'compressed' is LZF data with total (compressed) length 'sz'
* NOTE: uncompressed length is stored in quicklistNode->sz.
* When quicklistNode->zl is compressed, node->zl points to a quicklistLZF
*/
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
/* quicklist is a 32 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: -1 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor.
*/
typedef struct quicklist {
quicklistNode *head; //头结点
quicklistNode *tail; //尾节点
unsigned long count; /* total count of all entries in all ziplists */
unsigned int len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes *///负数代表级别,正数代表个数
unsigned int compress : 16; /* depth of end nodes not to compress;0=off *///压缩级别
} quicklist;quickList就是一个标准的双向链表的配置,有head 有tail;
每一个节点是一个quicklistNode,包含prev和next指针。
每一个quicklistNode 包含 一个ziplist,*zp 压缩链表里存储键值。
所以quicklist是对ziplist进行一次封装,使用小块的ziplist来既保证了少使用内存,也保证了性能。
到底一个quicklist节点包含多长的ziplist合适呢?
每个quicklist节点上的ziplist越短,则内存碎片越多。内存碎片多了,有可能在内存中产生很多无法被利用的小碎片,从而降低存储效率。这种情况的极端是每个quicklist节点上的ziplist只包含一个数据项,这就蜕化成一个普通的双向链表了。
每个quicklist节点上的ziplist越长,则为ziplist分配大块连续内存空间的难度就越大。有可能出现内存里有很多小块的空闲空间(它们加起来很多),但却找不到一块足够大的空闲空间分配给ziplist的情况。这同样会降低存储效率。这种情况的极端是整个quicklist只有一个节点,所有的数据项都分配在这仅有的一个节点的ziplist里面。这其实蜕化成一个ziplist了。
Redis提供了一个配置参数list-max-ziplist-size,就是为了让使用者可以来根据自己的情况进行调整。
我们来详细解释一下这个参数的含义。它可以取正值,也可以取负值。
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如,当这个参数配置成5的时候,表示每个quicklist节点的ziplist最多包含5个数据项。
当取负值的时候,表示按照占用字节数来限定每个quicklist节点上的ziplist长度。这时,它只能取-1到-5这五个值,每个值含义如下:
- -5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
- -4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
- -3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
- -2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)
- -1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
当列表很长的时候,最容易被访问的很可能是两端的数据,中间的数据被访问的频率比较低(访问起来性能也很低)。如果应用场景符合这个特点,那么list还提供了一个选项,能够把中间的数据节点进行压缩,从而进一步节省内存空间。Redis的配置参数list-compress-depth就是用来完成这个设置的。
这个参数表示一个quicklist两端不被压缩的节点个数。注:这里的节点个数是指quicklist双向链表的节点个数,而不是指ziplist里面的数据项个数。实际上,一个quicklist节点上的ziplist,如果被压缩,就是整体被压缩的。
图中例子对应的ziplist大小配置和节点压缩深度配置,如下:
list-max-ziplist-size 3
list-compress-depth 2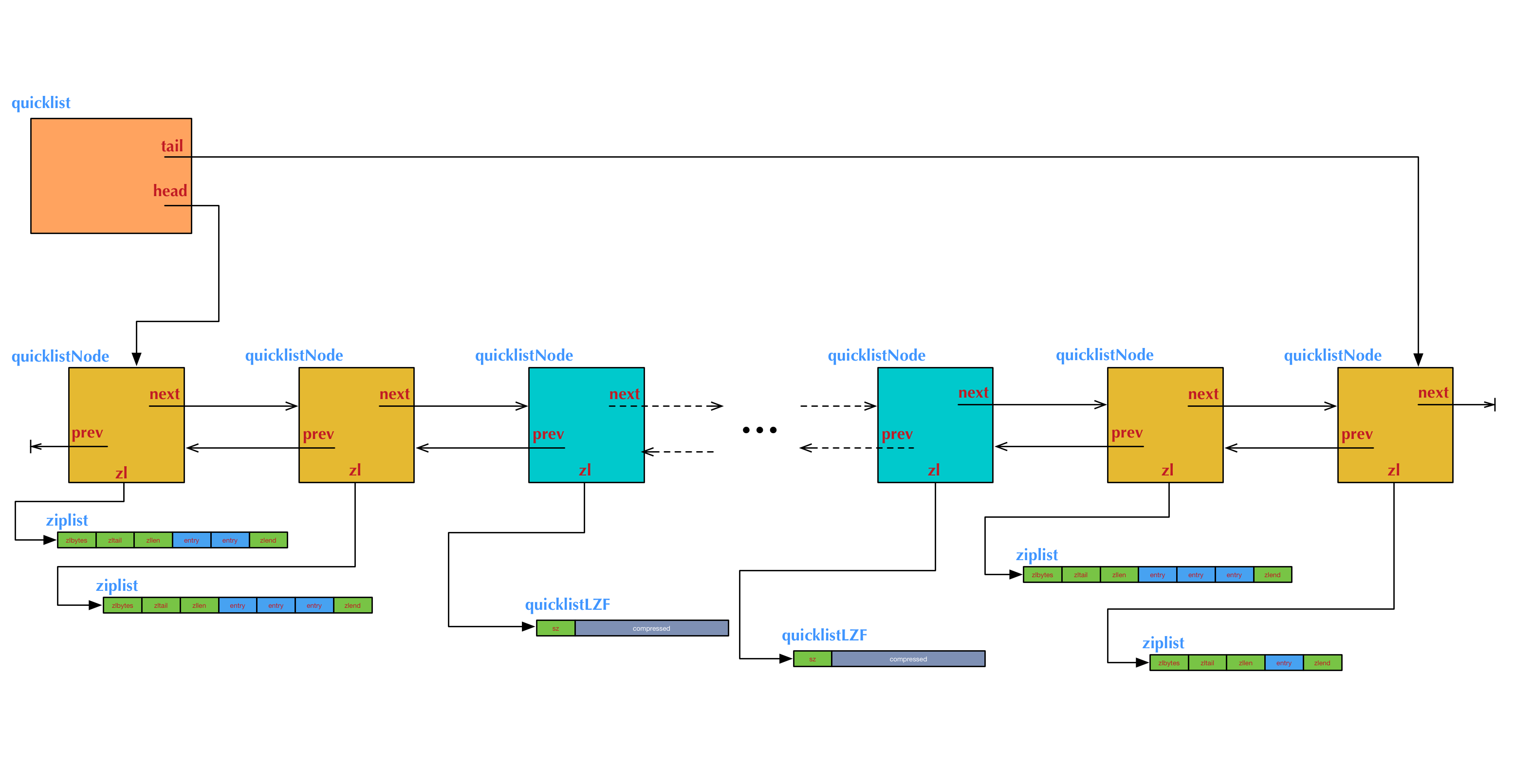
这个例子中我们需要注意的几点是:
- 两端各有2个橙黄色的节点,是没有被压缩的。它们的数据指针zl指向真正的ziplist。中间的其它节点是被压缩过的,它们的数据指针zl指向被压缩后的ziplist结构,即一个quicklistLZF结构。
- 左侧头节点上的ziplist里有2项数据,右侧尾节点上的ziplist里有1项数据,中间其它节点上的ziplist里都有3项数据(包括压缩的节点内部)。这表示在表的两端执行过多次push和pop操作后的一个状态。