

Redis作为一种存储字符串的缓存结构,其具体实现是由C语言完成,在C语言中,字符串是通过字符数组实现的,即char[],那么Redis对于字符串的实现是不是也是基于字符数组吗?不是的,Redis对字符串的处理是通过SDS(Simple Dynamic String)实现的。
SDS简单动态字符串,它是由C语言完成,如下是其简单的实现结构实现:
struct sdshdr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度
int free;
// 数据空间
char buf[];
};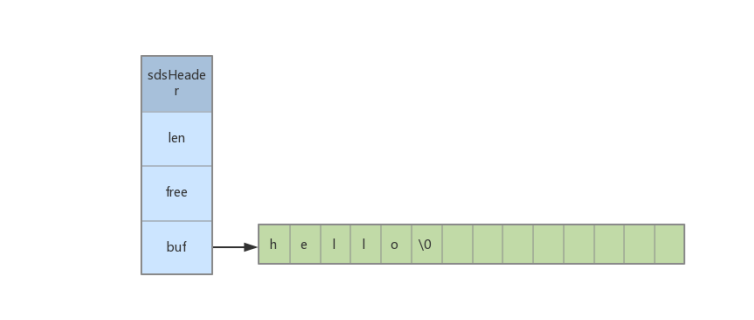
Redis的字符串也会遵守C语言的字符串的实现规则,即最后一个字符为空字符。然而这个空字符不会被计算在len里头。
5.0版本真实源码在sds.h文件中
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};- len:已使用的长度,即字符串的真实长度
- alloc:除去标头和终止符('\0')后的长度
- flags:低3位表示字符串类型,其余5位未使用
- buf[]:存储字符数据
你会发现同样一组结构 Redis 使用泛型定义了好多次,为什么不直接使用 int 类型呢?
因为当字符串比较短的时候,len 和 alloc 可以使用 byte 和 short 来表示,Redis 为了对内存做极致的优化,不同长度的字符串使用不同的结构体来表示。
SDS与C字符串的区别
C语言这种简单的字符串表示方式 不符合 Redis 对字符串在安全性、效率以及功能方面的要求。我们知道,C 语言使用了一个长度为 N+1 的字符数组来表示长度为 N 的字符串,并且字符数组最后一个元素总是 '\0'。
具体有一下几点
常数复杂度获取字符串长度
C字符串:
因为C语言并不记录自身的长度信息,所以获取一个C字符串的长度,程序必须遍历整个字符串,对遇到的,每个字符进行计数,直到遇到代表字符串结尾的空字符串为止,这个操作的复杂度为O(n)。
SDS:
与C语言不同的是,SDS结构中的属性length记录了SDS本身的长度,所以获取一个SDS长度的复杂度为O(1)。有人疑问那么SDS的length值是哪来的?这里的length值是SDS API在设置和更新SDS时自动完成的。
效果:通过使用SDS而不是C字符串,Redis获取字符串长度的复杂度由O(N)降为O(1),这确保了字符串长度的获取的工作不会成为Redis的性能瓶颈。
杜绝缓冲区溢出
C字符串:
由于C自身不记录字符串的长度带来一个问题是容易造成缓冲区溢出(buffer overflow)。在string.h/strcat函数中,可以将一个字符串拼接到另外一个字符串的末尾。
理想状态下,用户在使用这个函数时,假定C为dest分配了足够多的内存,可以容纳src字符串中的所有内容,而一旦这个假定不成立,就会产生缓冲区溢出。
如果执行strcat(s1," cluster");将Redis改为”Redis cluster“,但是粗心的却忘了在执行这句之前为s1分配足够的空间,那么在执行之后,s1的数据将会溢出到s2所在的空间,导致s2保存的内容意外的被修改。
SDS:
与C语言不同的是,SDS空间分配政策完全杜绝了发生缓冲区溢出的可能性:当SDS API需要对字符串进行修改时,首先会检查SDS的空间是否满足修改所需的要求,因为SDS自身有对字符串长度记录的属性length和空闲空间属性free,可以借助这两个参数进行检查。SDS会在执行动作之前判断SDS的空间大小,再去执行操作,如果空间不够的话,SDS API会自动扩展空间。
/* Append the specified binary-safe string pointed by 't' of 'len' bytes to the
* end of the specified sds string 's'.
*
* After the call, the passed sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call. */
sds sdscatlen(sds s, const void *t, size_t len) {
// 获取原字符串的长度
size_t curlen = sdslen(s);
// 按需调整空间,如果容量不够容纳追加的内容,就会重新分配字节数组并复制原字符串的内容到新数组中
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL; // 内存不足
memcpy(s+curlen, t, len); // 追加目标字符串到字节数组中
sdssetlen(s, curlen+len); // 设置追加后的长度
s[curlen+len] = '\0'; // 让字符串以 \0 结尾,便于调试打印
return s;
}减少修改字符串时带来的内存重分配次数
C字符串:
因为C字符串不记录自身长度,每次增长或者缩短字符串长度时,程序都要对这个C字符串数组进行一次内存重新分配操作,不然容易造成内存益出。因为内存,分配设计复杂的算法,并且可能需要执行系统调用,所以它通常是一个比较耗时和耗能的操作。但是Redis作为缓存,追求速度,所以不能经常发生内存分配操作。
SDS:
SDS数组中的未使用空间字节数量由SDS的属性free记录,通过free记录,SDS实现了空间预分配和惰性释放两种优化策略。
-
空间预分配
空间预分配用于优化SDS的字符串增长操作:当SDS的API对一个SDS进行修改,并且需要对SDS的空间进行扩展时,程序不仅会为SDS分配修改所需要的空间,而且还会为SDS分配额外的空间。额外的空间分配规则如下:
(1)如果修改SDS之后,SDS的长度小于1MB,那么程序会给SDS分配和length一样大的额外空间,这是SDSlength和free的值相等。举个例子,如果修改后的字符串长度为13k,那么SDS的空间将会占据13k+13k+1byte(额外的一个字节用于保存空字符串)。
2)如果修改SDS之后,SDS的长度大于1MB,那么程序会给SDS分配额外的1MB空间,举个例子,比如修改后的SDS有30MB的大小,那么程序会分配1MB的未使用空间,SDS的buf数组实际大小将是30MB+1MB+1byte。 -
惰性释放
惰性释放用于优化SDS的字符串缩短操作:当SDS的API要缩短SDS保存的字符串时,程序并不需要立即使用内存重分配策略来回收缩短后多出来的字节,而是使用free属性将这些字节记录起来,并等待使用。
二进制安全
C字符串中的字符必须符合某种编码(比如ASCII),并且除了字符串末尾之外,字符串里面不能包含空字符串,否则最先被程序读入的空字符串将被误认为是字符串结尾。
SDS
API都是二进制安全的,所有SDS API都会以处理二进制的方式来处理存放在SDS buf中的数据,数据写什么样,它被读取时就是什么样子。
兼容部分C字符串函数
SDS的API总会以SDS保存的数据的末尾设置为空字符串,并且在分配SDS空间时会多分配一个字节的空间来容纳空字符串,这是为了那些保存的数据可以重用一部分 string.h 库中的函数。
总结
SDS其实就是字符串数组的一个封装,但是由于考虑了多种场景,作者给它适配了多个高效、优雅的接口,使得SDS成为了一个存储字符串的优秀设计。使得SDS成为一个独立的、可提供高效优质服务的基础实体。
我们在设计一些偏底层的数据结构、对象、甚至是数据库表的时候,可以参考SDS的设计,从中寻找一些启发。