

B树也称B-树,它是一棵多路平衡查找树,B树不要和二叉树混淆,在计算机科学中,B树是一种自平衡树数据结构,它维护有序数据并允许以对数时间进行搜索,顺序访问,插入和删除。B树是二叉搜索树的一般化,因为节点可以有两个以上的子节点。与其他自平衡二进制搜索树不同,B树非常适合读取和写入相对较大的数据块(如光盘)的存储系统。它通常用于数据库和文件系统。
B树的特性
一棵m阶的B树的满足条件:
- 每个节点至多有m棵子树
- 根节点除外,其它每个分支节点至少有【m/2】棵子树
- 根节点至少有两棵子树(除非B树只包含一个节点)
- 所有叶子节点在同一层上,B树的叶子节点可以看成一种外部节点,不包含任何信息。
- 有j个孩子的非叶结点恰好有j-1个关键码,关键码按递增次序排列。


特点
B树相对于平衡二叉树的不同是,每个节点包含的关键字增多了,特别是在B树应用到数据库中的时候,数据库充分利用了磁盘块的原理(磁盘数据存储是采用块的形式存储的,每个块的大小为4K,每次IO进行数据读取时,同一个磁盘块的数据可以一次性读取出来)把节点大小限制和充分使用在磁盘快大小范围;把树的节点关键字增多后树的层级比原来的二叉树少了,减少数据查找的次数和复杂度;
插入操作
插入操作是指插入一条记录,即(key, value)的键值对。如果B树中已存在需要插入的键值对,则用需要插入的value替换旧的value。若B树不存在这个key,则一定是在叶子结点中进行插入操作。
1)根据要插入的key的值,找到叶子结点并插入。
2)判断当前结点key的个数是否小于等于m-1,若满足则结束,否则进行第3步。
3)以结点中间的key为中心分裂成左右两部分,然后将这个中间的key插入到父结点中,这个key的左子树指向分裂后的左半部分,这个key的右子支指向分裂后的右半部分,然后将当前结点指向父结点,继续进行第3步。
下面以5阶B树为例,介绍B树的插入操作,在5阶B树中,结点最多有4个key,最少有2个key
a)在空树中插入39

此时根结点就一个key,此时根结点也是叶子结点
b)继续插入22,97和41

根结点此时有4个key
c)继续插入53

插入后超过了最大允许的关键字个数4,所以以key值为41为中心进行分裂,结果如下图所示,分裂后当前结点指针指向父结点,满足B树条件,插入操作结束。当阶数m为偶数时,需要分裂时就不存在排序恰好在中间的key,那么我们选择中间位置的前一个key或中间位置的后一个key为中心进行分裂即可。

d)依次插入13,21,40,同样会造成分裂,结果如下图所示。

e)依次插入30,27, 33 ;36,35,34 ;24,29,结果如下图所示。

f)插入key值为26的记录,插入后的结果如下图所示。

当前结点需要以27为中心分裂,并向父结点进位27,然后当前结点指向父结点,结果如下图所示。

进位后导致当前结点(即根结点)也需要分裂,分裂的结果如下图所示。

删除操作
删除操作是指,根据key删除记录,如果B树中的记录中不存对应key的记录,则删除失败。
1)如果当前需要删除的key位于非叶子结点上,则用后继key(这里的后继key均指后继记录的意思)覆盖要删除的key,然后在后继key所在的子支中删除该后继key。此时后继key一定位于叶子结点上,这个过程和二叉搜索树删除结点的方式类似。删除这个记录后执行第2步
2)该结点key个数大于等于Math.ceil(m/2)-1,结束删除操作,否则执行第3步。
3)如果兄弟结点key个数大于Math.ceil(m/2)-1,则父结点中的key下移到该结点,兄弟结点中的一个key上移,删除操作结束。
否则,将父结点中的key下移与当前结点及它的兄弟结点中的key合并,形成一个新的结点。原父结点中的key的两个孩子指针就变成了一个孩子指针,指向这个新结点。然后当前结点的指针指向父结点,重复上第2步。
有些结点它可能即有左兄弟,又有右兄弟,那么我们任意选择一个兄弟结点进行操作即可。
下面以5阶B树为例,介绍B树的删除操作,5阶B树中,结点最多有4个key,最少有2个key
a)原始状态

b)在上面的B树中删除21,删除后结点中的关键字个数仍然大于等2,所以删除结束。

c)在上述情况下接着删除27。从上图可知27位于非叶子结点中,所以用27的后继替换它。从图中可以看出,27的后继为28,我们用28替换27,然后在28(原27)的右孩子结点中删除28。删除后的结果如下图所示。
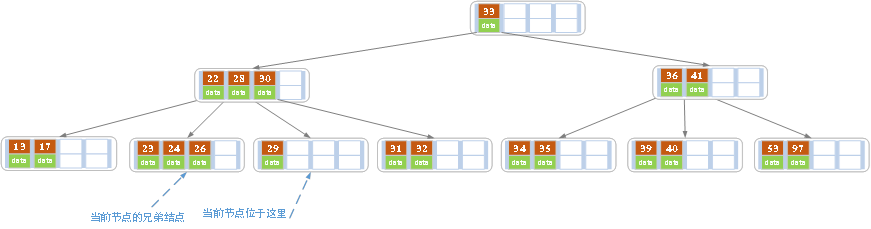
删除后发现,当前叶子结点的记录的个数小于2,而它的兄弟结点中有3个记录(当前结点还有一个右兄弟,选择右兄弟就会出现合并结点的情况,不论选哪一个都行,只是最后B树的形态会不一样而已),我们可以从兄弟结点中借取一个key。所以父结点中的28下移,兄弟结点中的26上移,删除结束。结果如下图所示。

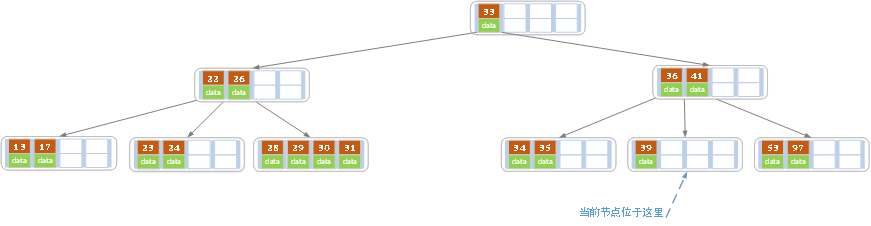
d)在上述情况下接着32,结果如下图。

当删除后,当前结点中只key,而兄弟结点中也仅有2个key。所以只能让父结点中的30下移和这个两个孩子结点中的key合并,成为一个新的结点,当前结点的指针指向父结点。结果如下图所示。

当前结点key的个数满足条件,故删除结束。
e)上述情况下,我们接着删除key为40的记录,删除后结果如下图所示。
同理,当前结点的记录数小于2,兄弟结点中没有多余key,所以父结点中的key下移,和兄弟(这里我们选择左兄弟,选择右兄弟也可以)结点合并,合并后的指向当前结点的指针就指向了父结点。
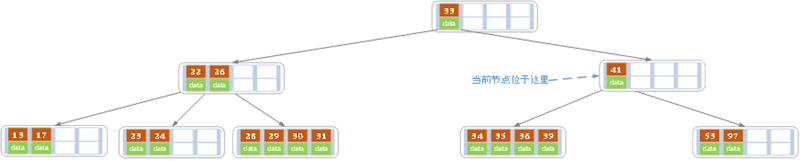
同理,对于当前结点而言只能继续合并了,最后结果如下所示。

总结
索引查询的数据主要受限于硬盘的I/O速度,查询I/O次数越少,速度越快,所以B树的结构才应需求而生;B树的每个节点的元素可以视为一次I/O读取,树的高度表示最多的I/O次数,在相同数量的总元素个数下,每个节点的元素个数越多,高度越低,查询所需的I/O次数越少;假设,一次硬盘一次I/O数据为8K,索引用int(4字节)类型数据建立,理论上一个节点最多可以为2000个元素,200020002000=8000000000,80亿条的数据只需3次I/O(理论值),可想而知,B树做为索引的查询效率有多高;