

Redis过期相关命令
Redis提供了四种命令来设置key的过期时间:
EXPIRE key seconds // 设置多少秒后过期
EXPIREAT key timestamp 设置 key 过期时间的时间戳(unix timestamp) 以秒计
PEXPIRE key milliseconds // 设置多少毫秒后过期
PEXPIREAT key milliseconds-timestamp // 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计虽然有四种不同的命令用于指定过期时间,但是实际上,无论使用哪一种命令,最终都会转换为 PEXPIREAT 命令来执行。
移除Redis的过期时间:
PERSIST key // 移除key的过期时间,key将保持永久查询剩余生存时间:
TTL key // 以秒为单位,返回给定 key 的剩余生存时间
PTTL key // 以毫秒为单位返回 key 的剩余的过期时间数据结构
那么,Redis是如何存储过期时间的呢?
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
clusterSlotToKeyMapping *slots_to_keys; /* Array of slots to keys. Only used in cluster mode (db 0). */
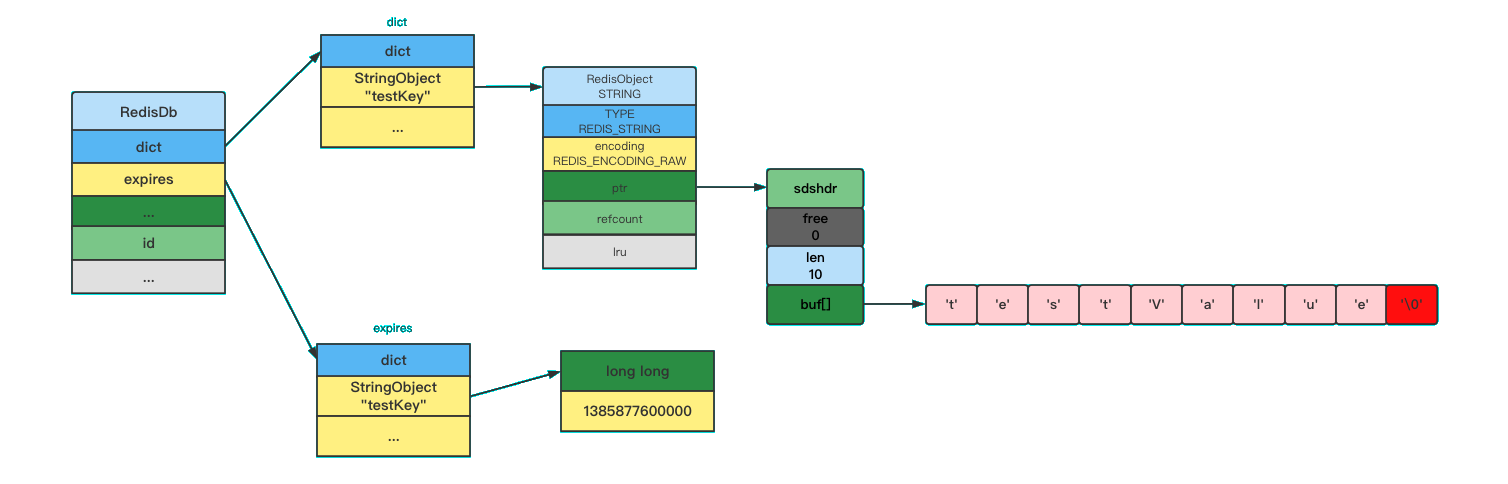
} redisDb;我们可以通过以上源码看出,redisDb 结构的 expires 这个字典保存了数据库中所有的过期时间,我们叫这个字典为过期字典。
每当我们为一个数据库的某一个键添加过期时间就会在该字典中添加一个键值对,键为这个需要添加过期时间的键,值为过期时间的时间戳。相反,如果删除一个键的过期时间,也会相应的操作这个字典,删除该键对应的过期时间键值对。如图所示:
过期删除策略
定时删除
当对一个key设置了过期时间,当该时间到,立即执行对该key的删除。
优点:定时删除对内存最友好,保证key一旦过期就能立即从内存中删除。
缺点:对CPU最不友好,在过期键比较多的时候,删除过期键会占用一部分CPU时间,对服务器的响应时间和吞吐量造成影响。
惰性删除
当一个key被设置过期时间后,当key的过期时间到了,并不会立即从内存中删除;在我们使用该key时,先检查其是否过期,过期则将其从内存中删除。
优点:对CPU友好、只在使用的时候才会进行过期检查,对于没用到的key不会浪费时间进行过期检查。
缺点:对内存不好用,key过期了,却一直没被使用,就会一直占这内存。如果数据库中存在很多过期键不被使用,便永远不会被被删除,内存不会被释放,从而造成内存泄漏。
定期删除
每隔一段时间(该时间段可设置),随机抽取一些设置了过期时间的key进行检查,删除里面过期的键。
优点:可以通过限制删除操作执行的时长和频率来减少删除操作对 CPU 的影响。另外定期删除,也能有效释放过期键占用的内存。
缺点:难以确定删除操作执行的时长和频率。如果执行的太频繁,定期删除策略变得和定时删除策略一样,对CPU不友好。如果执行的频率小,就和惰性删除一样了,过期键占用的内存不会及时得到释放。
另外最重要的是,在获取某个键时,如果某个键的过期时间已经到了,但是还没执行定期删除,那么就会返回这个键的值,这是业务不能忍受的错误。
Redis过期删除策略
通过前面讨论的三种过期删除策略,可以发现单一使用某一策略都不能满足实际需求,所以实际的应用都是组合使用的,而 Redis 使用的过期删除策略就是:惰性删除和定期删除两种策略的组合。
惰性删除策略的实现
Redis 的惰性删除策略由 db.c/expireIfNeeded 函数实现,所有键读写命令执行之前都会调用 expireIfNeeded 函数对其进行检查,如果过期,则删除该键,然后执行键不存在的操作;未过期则不作操作,继续执行原有的命令。
/* This function is called when we are going to perform some operation
* in a given key, but such key may be already logically expired even if
* it still exists in the database. The main way this function is called
* is via lookupKey*() family of functions.
*
* The behavior of the function depends on the replication role of the
* instance, because by default replicas do not delete expired keys. They
* wait for DELs from the master for consistency matters. However even
* replicas will try to have a coherent return value for the function,
* so that read commands executed in the replica side will be able to
* behave like if the key is expired even if still present (because the
* master has yet to propagate the DEL).
*
* In masters as a side effect of finding a key which is expired, such
* key will be evicted from the database. Also this may trigger the
* propagation of a DEL/UNLINK command in AOF / replication stream.
*
* On replicas, this function does not delete expired keys by default, but
* it still returns 1 if the key is logically expired. To force deletion
* of logically expired keys even on replicas, set force_delete_expired to
* a non-zero value. Note though that if the current client is executing
* replicated commands from the master, keys are never considered expired.
*
* The return value of the function is 0 if the key is still valid,
* otherwise the function returns 1 if the key is expired. */
int expireIfNeeded(redisDb *db, robj *key, int force_delete_expired) {
if (!keyIsExpired(db,key)) return 0;
/* If we are running in the context of a replica, instead of
* evicting the expired key from the database, we return ASAP:
* the replica key expiration is controlled by the master that will
* send us synthesized DEL operations for expired keys. The
* exception is when write operations are performed on writable
* replicas.
*
* Still we try to return the right information to the caller,
* that is, 0 if we think the key should be still valid, 1 if
* we think the key is expired at this time.
*
* When replicating commands from the master, keys are never considered
* expired. */
if (server.masterhost != NULL) {
if (server.current_client == server.master) return 0;
if (!force_delete_expired) return 1;
}
/* If clients are paused, we keep the current dataset constant,
* but return to the client what we believe is the right state. Typically,
* at the end of the pause we will properly expire the key OR we will
* have failed over and the new primary will send us the expire. */
if (checkClientPauseTimeoutAndReturnIfPaused()) return 1;
/* Delete the key */
deleteExpiredKeyAndPropagate(db,key);
return 1;
}定期删除策略的实现
该策略由 activeExpireCycle 函数实现,每当服务器周期性的操作serverCron函数执行的时候,activeExpireCycle 函数就会被调用,在规定的时间内,分多次遍历服务器中的各个数据库,从数据库的expires字典中随你检查一部分的过期时间,并删除其中的过期键。具体代码实现由于太多,有感兴趣可以去看一下,redis6在expire.c中,redis3在redis.c中。
需要注意的是: Redis 的定期删除策略并不是一次运行就检查所有的库、所有的键,而是随机检查一定数量的键。
定期删除函数的运行频率,在 Redis2.6 版本中,规定每秒运行 10 次,大概 100ms 运行一次。在 Redis2.8 版本后,可以通过修改配置文件 redis.conf 的 hz 选项来调整这个次数:
# The range is between 1 and 500, however a value over 100 is usually not
# a good idea. Most users should use the default of 10 and raise this up to
# 100 only in environments where very low latency is required.
hz 10随机抽取一些检测,一些是多少?同样是由redis.conf文件中的 maxmemory-samples 属性决定的,默认为5。
# LRU, LFU and minimal TTL algorithms are not precise algorithms but approximated
# algorithms (in order to save memory), so you can tune it for speed or
# accuracy. For default Redis will check five keys and pick the one that was
# used less recently, you can change the sample size using the following
# configuration directive.
#
# The default of 5 produces good enough results. 10 Approximates very closely
# true LRU but costs more CPU. 3 is faster but not very accurate.
#
# maxmemory-samples 5定期删除+惰性删除存在的问题
如果某个key过期后,定期删除没删除成功,然后也没再次去请求key,也就是说惰性删除也没生效。这时,如果大量过期的key堆积在内存中,redis的内存会越来越高,导致redis的内存块耗尽。那么就应该采用内存淘汰机制。
AOF、RDB对过期键的处理
生成RDB文件
在执行SAVE或者BGSAVE命令创建一个新的RDB文件的时候,程序会对数据库中的过期键进行检查,过期的键不会被保存到新创建的RDB文件中。
载入RDB文件
载入的时候分为两种情况
- 服务器以主服务器运行。当服务器以主服务器运行的时候,会对文件中保存的键进行检查,未过期的键会被载入到数据库中,而过期的键则会被忽略,所以过期键对载入RDB文件的主服务器不会造成影响。
- 服务器以从服务器运行。当服务器以从服务器运行的时候,会将文件中保存的所有键进行保存,不论是否过期。但是由于主从服务器进行数据同步的时候,从服务器的数据库就会被清空,所以一般来讲,过期键载入RDB文件的从高服务器也不会造成影响。
AOF文件的写入
当数据库中某个键已经过期,但是它还没有被惰性删除或者定期删除,那么AOF文件不会因为这个过期键而产生任何影响。当过期键被惰性删除或者定期删除之后,程序会向AOF文件追加一条DEL命令进行显示的删除。
AOF文件的重写
重写的时候程序会对数据库中的键进行检查,已过期的键不会被保存到重写后的AOF文件中。
当服务器运行在主从复制模式下的时候,从服务器的过期键删除动作是由主服务器控制的。主服务器在删除一个过期键后,会显示的向所有从服务器发送一个DEL命令,命令从服务器删除这个键;从服务器在执行客户端发送的命令的时候,即使遇到过期的键也不会将过期的键进行删除,是继续像处理未过期的键一样来处理过期键;从服务器只有在接到主服务器发送来的DEL命令的时候才会删除过期键。
内存淘汰策略
Redis的内存用完了会发生什么?如果达到设置的上限(默认noeviction)时,Redis的写命令会返回oom错误信息(读命令还可以正常返回)。
redis.exceptions.ResponseError, OOM command not allowed when used memory > 'maxmemory'Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
全局的键空间选择性移除
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。(默认)
- allkeys-lru(least recently used):当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。(常用)
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
- allkeys-lfu(least frequently used):当内存不足以容纳新写入数据时,在键空间中,移除最近频率最少使用的key。
设置过期时间的键空间选择性移除
- volatile-lru(least recently used):当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
- volatile-lfu(least frequently used):当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近频率最少使用的key。
# Set a memory usage limit to the specified amount of bytes.
# When the memory limit is reached Redis will try to remove keys
# according to the eviction policy selected (see maxmemory-policy).
#
# If Redis can't remove keys according to the policy, or if the policy is
# set to 'noeviction', Redis will start to reply with errors to commands
# that would use more memory, like SET, LPUSH, and so on, and will continue
# to reply to read-only commands like GET.
#
# This option is usually useful when using Redis as an LRU or LFU cache, or to
# set a hard memory limit for an instance (using the 'noeviction' policy).
#
# WARNING: If you have replicas attached to an instance with maxmemory on,
# the size of the output buffers needed to feed the replicas are subtracted
# from the used memory count, so that network problems / resyncs will
# not trigger a loop where keys are evicted, and in turn the output
# buffer of replicas is full with DELs of keys evicted triggering the deletion
# of more keys, and so forth until the database is completely emptied.
#
# In short... if you have replicas attached it is suggested that you set a lower
# limit for maxmemory so that there is some free RAM on the system for replica
# output buffers (but this is not needed if the policy is 'noeviction').
#
# maxmemory <bytes>
# MAXMEMORY POLICY: how Redis will select what to remove when maxmemory
# is reached. You can select among five behaviors:
#
# volatile-lru -> Evict using approximated LRU among the keys with an expire set.
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU among the keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key among the ones with an expire set.
# allkeys-random -> Remove a random key, any key.
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> Don't evict anything, just return an error on write operations.
#
# LRU means Least Recently Used
# LFU means Least Frequently Used
#
# Both LRU, LFU and volatile-ttl are implemented using approximated
# randomized algorithms.
#
# Note: with any of the above policies, Redis will return an error on write
# operations, when there are no suitable keys for eviction.
#
# At the date of writing these commands are: set setnx setex append
# incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd
# sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby
# zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby
# getset mset msetnx exec sort
#
# The default is:
#
# maxmemory-policy noeviction淘汰算法
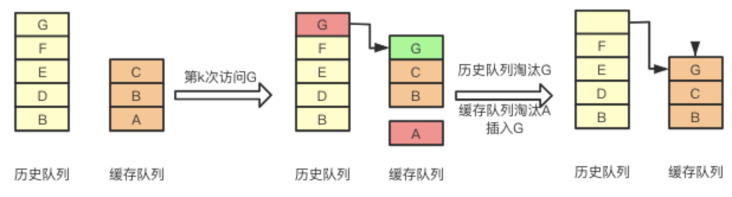
FIFO
FIFO(First in First out)先进先出。可以理解为是一种类似队列的算法实现。
最先进来的数据,被认为在未来被访问的概率也是最低的,因此,当规定空间用尽且需要放入新数据的时候,会优先淘汰最早进来的数据。
- 优点:最简单、最公平的一种数据淘汰算法,逻辑简单清晰,易于实现
- 缺点:这种算法逻辑设计所实现的缓存的命中率是比较低的,因为没有任何额外逻辑能够尽可能的保证常用数据不被淘汰掉
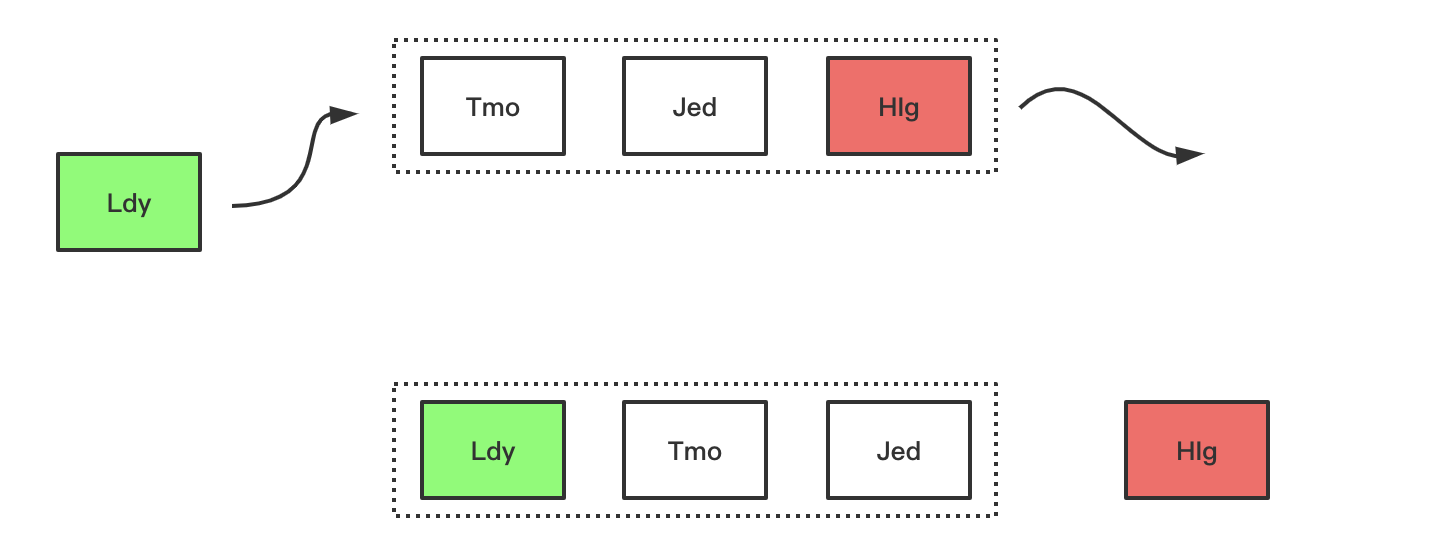
下面简单演示了FIFO的工作过程,假设存放元素尺寸是3,且队列已满,放置元素顺序如下图所示,当来了一个新的数据“ldy”后,因为元素数量到达了阈值,则首先要进行太淘汰置换操作,然后加入新元素,操作如图展示:

LRU
LRU(The Least Recently Used)最近最久未使用算法。相比于FIFO算法智能些。
如果一个数据最近很少被访问到,那么被认为在未来被访问的概率也是最低的,当规定空间用尽且需要放入新数据的时候,会优先淘汰最久未被访问的数据。
- 优点:LRU可以有效的对访问比较频繁的数据进行保护,也就是针对热点数据的命中率提高有明显的效果。
- 缺点:对于周期性、偶发性的访问数据,有大概率可能造成缓存污染,也就是置换出去了热点数据,把这些偶发性数据留下了,从而导致LRU的数据命中率急剧下降。
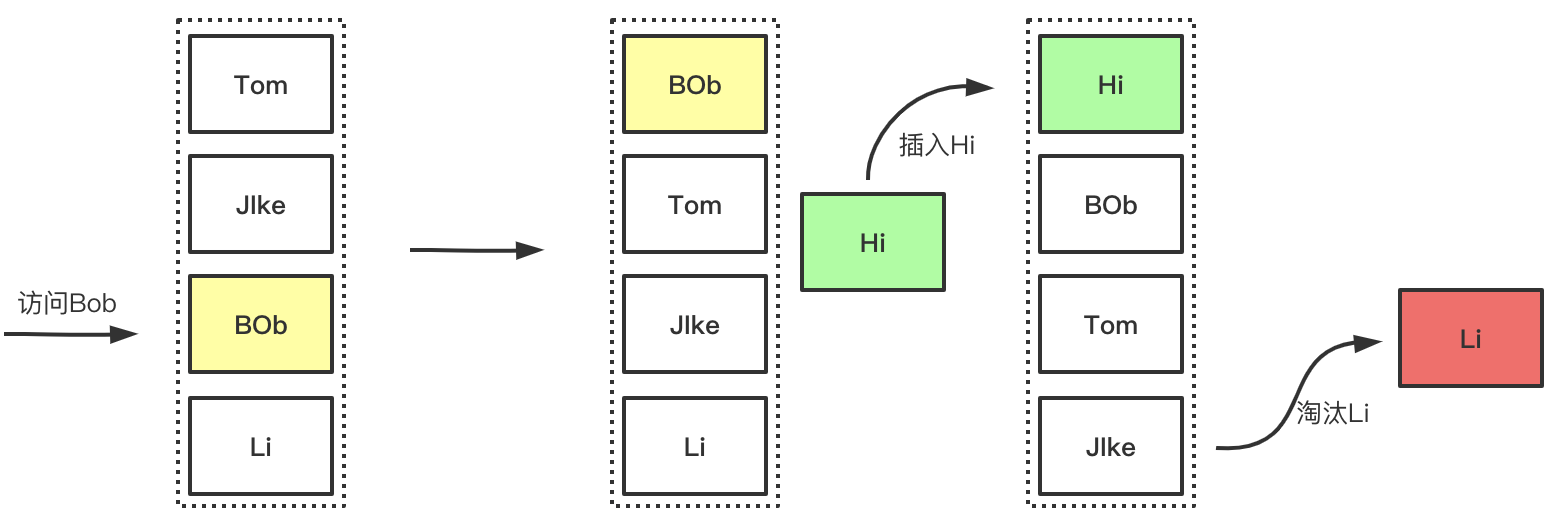
下图展示了LRU简单的工作过程,访问时对数据的提前操作,以及数据满且添加新数据的时候淘汰的过程的展示如下:
LRU变种
如上所述,对于偶发性、周期性的数据没有良好的抵抗力,很容易就造成缓存的污染,影响命中率,因此衍生出了很多的LRU算法的变种,用以处理这种偶发冷数据突增的场景,目的就是当判别数据为偶发或周期的冷数据时,不会存入空间内,从而降低热数据的淘汰率,比如:LRU-K、Two Queues等。
LRU-K
LRU-K中的K其实是指最近访问元素的次数,传统LRU与此对比则可以认为传统LRU是LRU-1。其核心思想就是将访问一次就能替代的“1”提升为"K"。
LRU-K算法需要维护两个队列:历史队列和缓存队列。
- 历史队列:用于记录元素的访问次数,当尚未达到K次时则继续保存,直至历史队列满了,采用的淘汰策略(FIFO、LRU)进行淘汰。
- 缓存队列:当历史队列中的元素访问次数达到K的时候,才会进入缓存队列。当该队列面了之后,淘汰最后一个元素,也就是第K次访问距离现在最久的那个元素。
原理解析
元素第一次被访问,添加到历史队列中。当历史队列中的元素满了,根据一定的缓存策略(FIFO、LRU)进行淘汰老的元素。
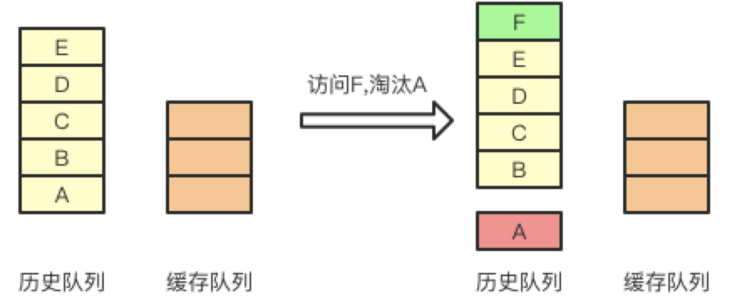
当历史队列中的某个元素第k次访问时,该元素从历史队列中出栈,并存放至缓存队列。
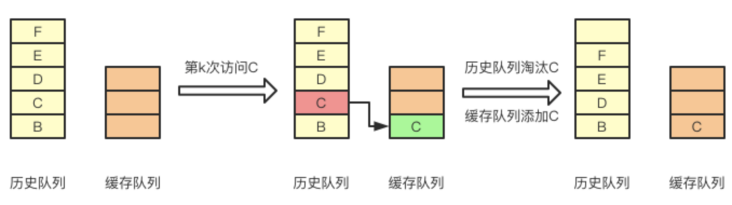
缓存队列中的元素再次被访问k次时,历史队列中该元素出栈,并且更新缓存队列中该元素的位置。

当缓存队列需要淘汰元素时,淘汰最后一个元素,也就是第k次访问距离现在最久的那个元素。
小结
它的命中率要比LRU要高,但是因为需要维护一个历史队列,因此内存消耗会比LRU多。
实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
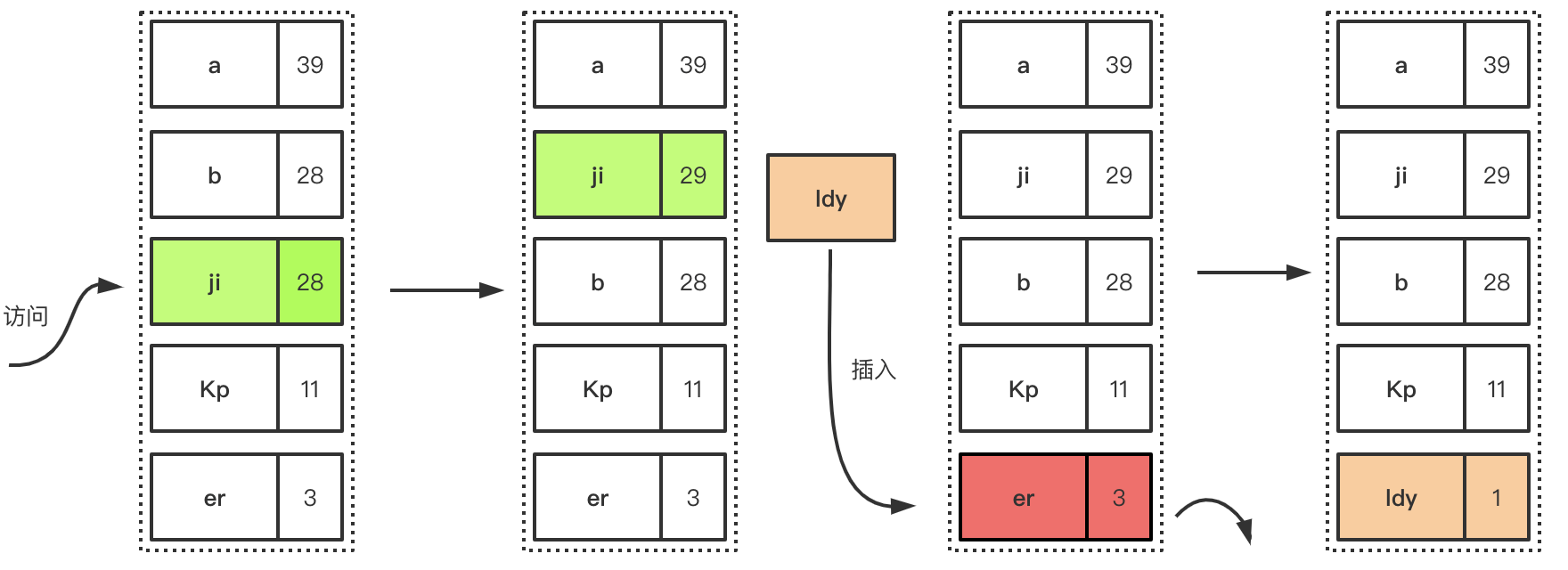
LFU
LFU(The Least Frequently Used)最近很少使用算法,与LRU的区别在于LRU是以时间衡量,LFU是以时间段内的次数
如果一个数据在一定时间内被访问的次数很低,那么被认为在未来被访问的概率也是最低的,当规定空间用尽且需要放入新数据的时候,会优先淘汰时间段内访问次数最低的数据。
- 优点:LFU也可以有效的保护缓存,相对场景来讲,比LRU有更好的缓存命中率。因为是以次数为基准,所以更加准确,自然能有效的保证和提高命中率。
- 缺点:因为LFU需要记录数据的访问频率,因此需要额外的空间;当访问模式改变的时候,算法命中率会急剧下降,这也是他最大弊端。
下面描述了LFU的简单工作过程,首先是访问元素增加元素的访问次数,从而提高元素在队列中的位置,降低淘汰优先级,后面是插入新元素的时候,因为队列已经满了,所以优先淘汰在一定时间间隔内访问频率最低的元素。
小结
- FIFO,先进先出算法。判断被存储的时间,离目前最远的数据优先被淘汰,可以使用队列实现。
- LRU,最近最少使用算法。判断最近被使用的时间,目前最远的数据优先被淘汰,可以使用双向链表和哈希表实现。
- LFU,最不经常使用算法,在一段时间内,数据被使用次数最少的,优先被淘汰,可以使用双哈希表实现。