

Redis是一种基于键值对(Key-Value)的NoSQL数据库,Redis的Value可以由String,hash,list,set,zset,Bitmaps,HyperLogLog等多种数据结构和算法组成。Redis还提供了键过期,发布订阅,事务,Lua脚本,哨兵,Cluster等功能。Redis执行命令的速度非常快,根据官方给的性能可以达到10w+qps。那么本文主要介绍到底Redis快在哪里,主要有以下几点:
开发语言
现在我们都用高级语言来编程,比如Java、python等。也许你会觉得C语言很古老,但是它真的很有用,毕竟unix系统就是用C实现的,所以C语言是非常贴近操作系统的语言。Redis就是用C语言开发的,所以执行会比较快。
内存操作
Redis的操作都是基于内存的,CPU不是 Redis 性能瓶颈,,Redis 的瓶颈是机器内存和网络带宽。
在计算机的世界中,CPU的速度是远大于内存的速度的,同时内存的速度也是远大于硬盘的速度。Redis的操作都是基于内存的,绝大部分请求是纯粹的内存操作,非常迅速。
最后以一张图量化系统的各种延时时间。
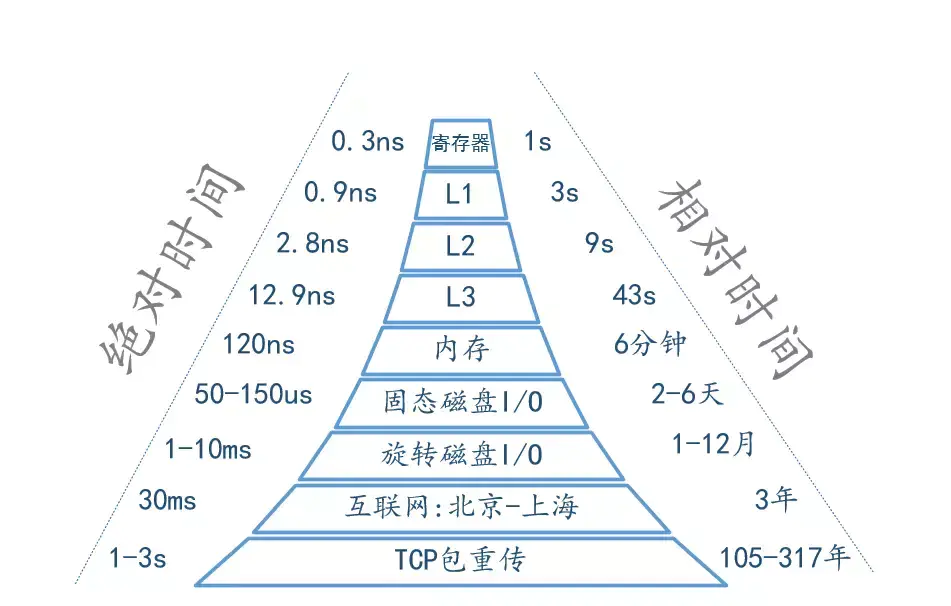
数据结构
学习 MySQL 的时候我知道为了提高检索速度使用了 B+ Tree 数据结构,所以 Redis 速度快应该也跟数据结构有关。
Redis 一共有 5 种数据类型,String、List、Hash、Set、SortedSet。
不同的数据类型底层使用了一种或者多种数据结构来支撑,目的就是为了追求更小的占用&更快的速度。
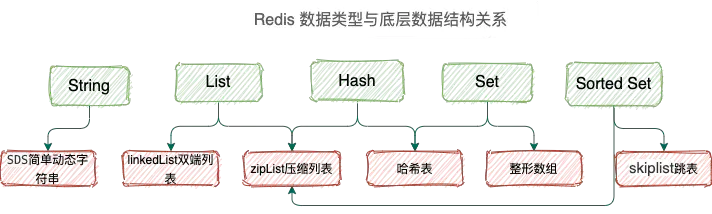
单线程操作
使用单线程可以省去多线程时CPU上下文会切换的时间,也不用去考虑各种锁的问题,不存在加锁释放锁操作,没有死锁问题导致的性能消耗。对于内存系统来说,多次读写都是在一个CPU上,没有上下文切换效率就是最高的!既然单线程容易实现,而且 CPU 不会成为瓶颈,那就顺理成章的采用单线程的方案了。
当然了,单线程也会有它的缺点,也是Redis的噩梦:阻塞。如果执行一个命令过长,那么会造成其他命令的阻塞,对于Redis是十分致命的,所以Redis是面向快速执行场景的数据库。
Redis 单线程指的是网络请求模块使用了一个线程,即一个线程处理所有网络请求,其他模块该使用多线程,仍会使用了多个线程。
多路I/O复用
Redis使用epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll的read、write、close等都转换成事件,不在网络I/O上浪费过多的时间。实现对多个FD读写的监控,提高性能。
具体实现见Reactor。
Reactor 设计模式
Redis基于Reactor模式开发了自己的网络事件处理器,称之为文件事件处理器(File Event Hanlder)。文件事件处理器由Socket、IO多路复用程序、文件事件分派器(dispather),事件处理器(handler)四部分组成。
本质上来说,事件驱动框架是基于操作系统提供的 IO 多路复用机制进行了封装,并加上了时间事件的处理。
当然这里有一个前提,就是 Redis 几乎所有数据读取和处理都是在内存中操作的,服务端对单个客户端的读写请求处理时间极短。