

MySQL的B+树索引在单列索引上比较好理解,结构如下:

那组合索引的B+树存储结构是什么样的呢,为什么会有最左前缀原理。
错误案例
原始表,Col1是主键。

对 col3 和 col2 建立 联合索引

正确案例
原始表

对 b c d 建立 联合索引
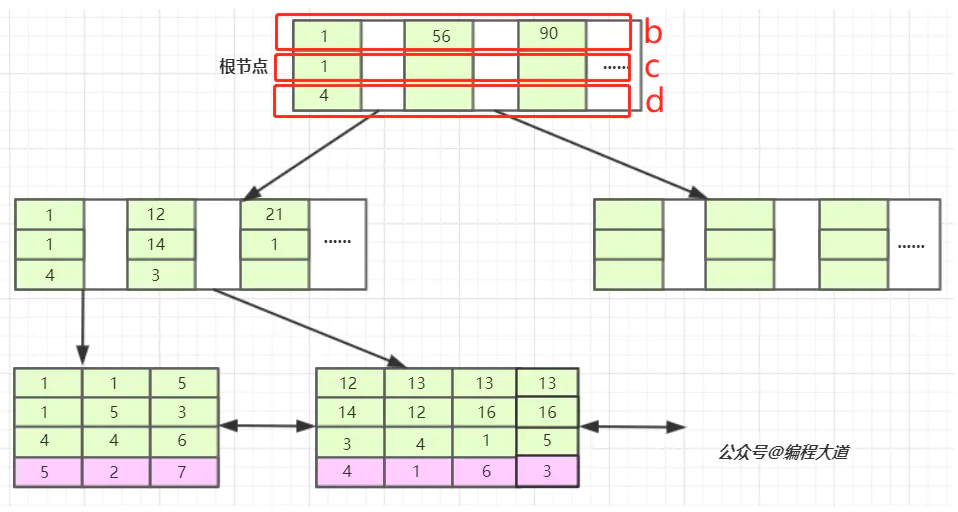
联合索引的查找方式
当我们的SQL语言可以应用到索引的时候,比如 select * from T1 where b = 12 and c = 14 and d = 3; 也就是T1表中a列为4的这条记录。存储引擎首先从根节点(一般常驻内存)开始查找,第一个索引的第一个索引列为1,12大于1,第二个索引的第一个索引列为56,12小于56,于是从这俩索引的中间读到下一个节点的磁盘文件地址,从磁盘上Load这个节点,通常伴随一次磁盘IO,然后在内存里去查找。当Load叶子节点的第二个节点时又是一次磁盘IO,比较第一个元素,b=12,c=14,d=3完全符合,于是找到该索引下的data元素即ID值,再从主键索引树上找到最终数据。
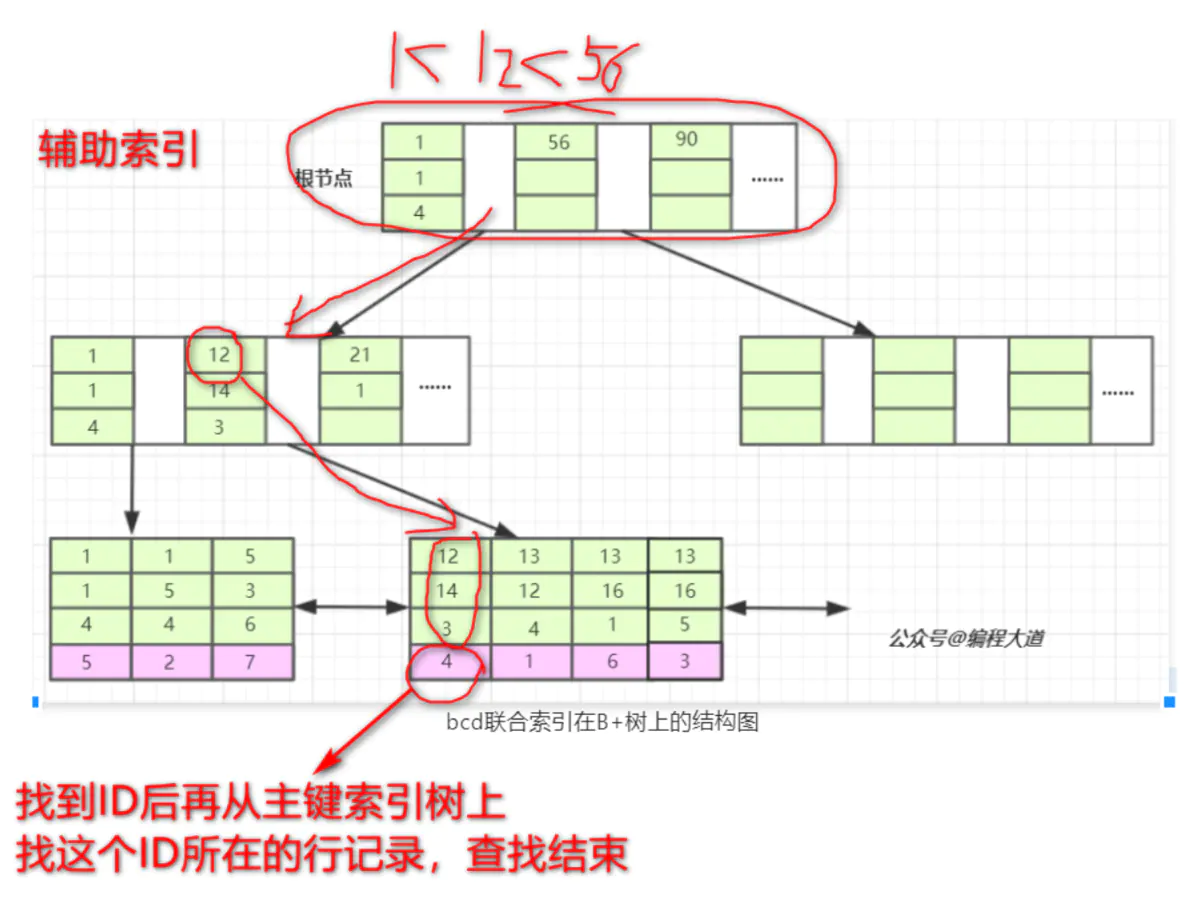
最左前缀匹配原则
之所以会有最左前缀匹配原则和联合索引的索引构建方式及存储结构是有关系的。
首先我们创建的idx_t1_bcd(b,c,d)索引,相当于创建了(b)、(b、c)(b、c、d)三个索引,看完下面你就知道为什么相当于创建了三个索引。
我们看,联合索引是首先使用多列索引的第一列构建的索引树,用上面idx_t1_bcd(b,c,d)的例子就是优先使用b列构建,当b列值相等时再以c列排序,若c列的值也相等则以d列排序。我们可以取出索引树的叶子节点看一下。

索引的第一列也就是b列可以说是从左到右单调递增的,但我们看c列和d列并没有这个特性,它们只能在b列值相等的情况下这个小范围内递增,如第一叶子节点的第1、2个元素和第二个叶子节点的后三个元素。
由于联合索引是上述那样的索引构建方式及存储结构,所以联合索引只能从多列索引的第一列开始查找。所以如果你的查找条件不包含b列如(c,d)、(c)、(d)是无法应用缓存的,以及跨列也是无法完全用到索引如(b,d),只会用到b列索引。
关于为什么在非子叶结点也要存在 c d 字段,猜测和索引下推有关,在上层索引树检索时就能把不符合的数据清洗掉以减少I/O与回表。