

定义
堆就是用数组实现的二叉树,所以它没有使用父指针或者子指针。堆根据“堆属性”来排序,“堆属性”决定了树中节点的位置。
堆就基于完全二叉树的结构(完全二叉树就是除了最底层,其它层都必须填满,最后一层可以从左到右填满);平时生活中,我们有时会说一堆人,一堆某某东西,其实数据结构里的堆也和生活中的类似,不同的就是数据结构里的堆是由一些按照某种优先级来组织成的队列,所以堆又叫做优先队列,显而易见,堆是可以把某种优先级最高或者最低的那个对象快速的取出,在想要实现这种类似功能的时候很有用。
堆属性
堆分为两种:最大堆和最小堆,两者的差别在于节点的排序方式。
在最大堆中,父节点的值比每一个子节点的值都要大。在最小堆中,父节点的值比每一个子节点的值都要小。这就是所谓的“堆属性”,并且这个属性对堆中的每一个节点都成立。

根据这一属性,那么最大堆总是将其中的最大值存放在树的根节点。而对于最小堆,根节点中的元素总是树中的最小值。堆属性非常有用,因为堆常常被当做优先队列使用,因为可以快速地访问到“最重要”的元素。
堆的根节点中存放的是最大或者最小元素,但是其他节点的排序顺序是未知的。例如,在一个最大堆中,最大的那一个元素总是位于 index 0 的位置,但是最小的元素则未必是最后一个元素。唯一能够保证的是最小的元素是一个叶节点,但是不确定是哪一个。
堆和普通树的区别
堆并不能取代二叉搜索树,它们之间有相似之处也有一些不同。我们来看一下两者的主要差别:
节点的顺序
在二叉搜索树中,左子节点必须比父节点小,右子节点必须必比父节点大。但是在堆中并非如此。在最大堆中两个子节点都必须比父节点小,而在最小堆中,它们都必须比父节点大。
内存占用
普通树占用的内存空间比它们存储的数据要多。你必须为节点对象以及左/右子节点指针分配内存。堆仅仅使用一个数据来存储数组,且不使用指针。
平衡
二叉搜索树必须是“平衡”的情况下,其大部分操作的复杂度才能达到O(log n)。你可以按任意顺序位置插入/删除数据,或者使用 AVL 树或者红黑树,但是在堆中实际上不需要整棵树都是有序的。我们只需要满足堆属性即可,所以在堆中平衡不是问题。因为堆中数据的组织方式可以保证O(log n) 的性能。
搜索
在二叉树中搜索会很快,但是在堆中搜索会很慢。在堆中搜索不是第一优先级,因为使用堆的目的是将最大(或者最小)的节点放在最前面,从而快速的进行相关插入、删除操作。
从数组到树
用数组来实现树相关的数据结构也许看起来有点古怪,但是它在时间和空间上都是很高效的。节点在数组中的位置index 和它的父节点以及子节点的索引之间有一个映射关系。
如果 i 是节点的索引,那么下面的公式就给出了它的父节点和子节点在数组中的位置:
parent(i) = floor((i - 1)/2)
left(i) = 2i + 1
right(i) = 2i + 2
在堆中主要是插入和删除节点的操作,这两种操作无论是哪一种,完成之后都还是一个堆,操作时要进行堆的调整,使其是个新堆。
添加新节点
当插入一个元素时,先将这个元素插入到队列尾,然后将这个新插入的元素和它的父节点进行优先权的比较,如果比父节点的优先权要大,则和父节点呼唤位置,然后再和新的父节比较,直到比新的父节点优先权小为止,总之就是不断地和父节点比较。
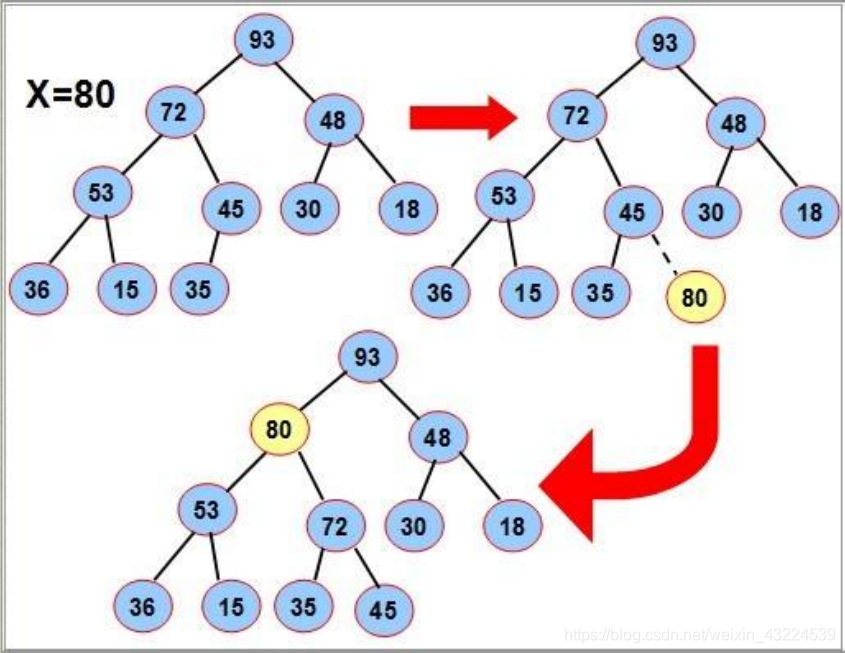
删除节点
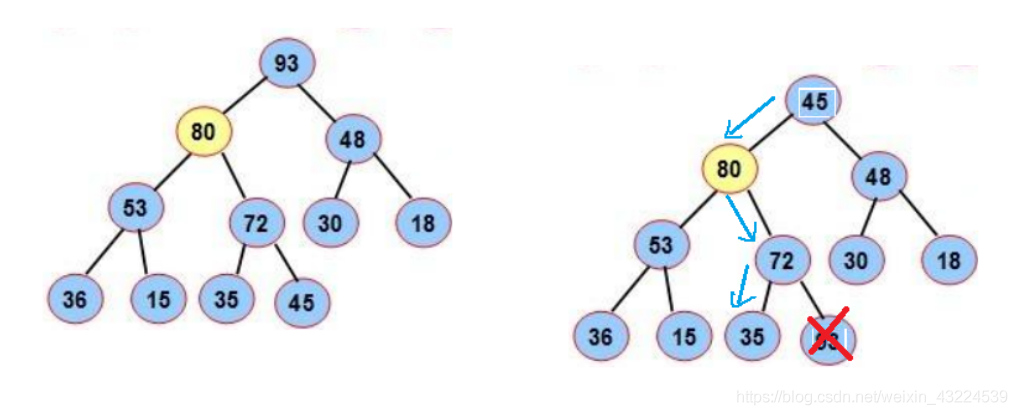
删除堆是删除堆顶的数据,将堆顶的数据根最后一个数据一换,然后删除数组最后一个数据,再进行向下调整算法。重复这个过程,直到秩序正常。
堆排序
将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。时间复杂度:O(n * log n)。
