

定义
数组是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
优点
随机访问性强,查找速度快,时间复杂度是O(1)。
缺点
- 从头部删除、从头部插入的效率低,时间复杂度是O(n),因为需要相应的向前搬移和向后搬移
- 空间利用率不高
- 内存空间要求高,必须要有足够的连续的内存空间
- 数组的空间大小是固定的,不能进行动态扩展
连续内存和同一数据类型
正是因为连续内存和相同数据类型这个特点,才使得数组的随机下标访问有了O(1)的时间复杂度,那么具体是怎么做到的呢?对于数组的元素,使用下标访问的时候,其所在地址的计算公式为
address = base_address + i * data_type_length
即根据首地址及下标和数据类型长度即可计算出数组中任意元素在内存的地址偏移量,然后根据该地址进行访问。如下图,根据公式,可直接通过下标得到内存地址偏移量,从而做到快速的随机访问。
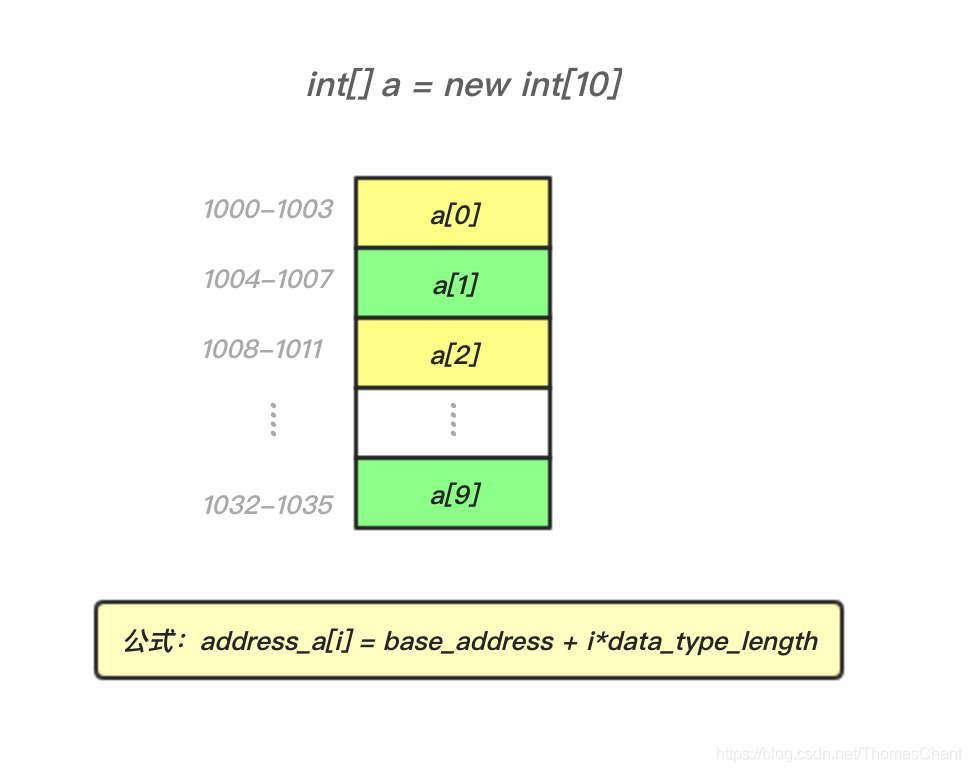
为什么大多数编程语言中,数组要从0开始编号,而不是1开始呢?
从数组的存储模型上来看,“下标”最确切的定义应该是“偏移量(offset)”。
如果用a代表数组的首地址,a[0]就是偏移量为0的位置,也就是首地址,a[k]就表示偏移量k个 type_size 的位置,所以计算 a[k] 的内存地址只需要用这个公式:
a[k]_address = base_address + i * data_type_length
但是,如果数组从 1 开始计数,那我们计算数组元素 a[k] 的内存地址就会变为:
a[k]_address = base_address + (i-1)*data_type_length
如果从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对CPU来说就是多了一次减法指令。