

1字节 = 8位 = 11111111 = 255
如果是INT
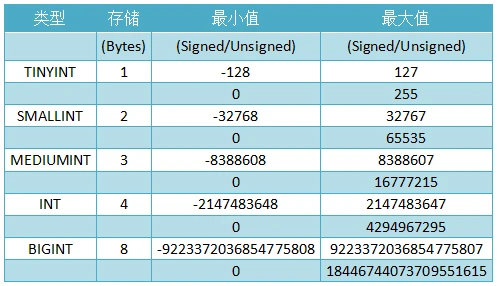
对于int类型的一些基础知识其实上图已经说的很明白了,在这里想讨论下常用的int(11)代表什么意思,很长时间以来我都以为这代表着限制int的长度为11位,直到有天看到篇文章才明白,11代表的并不是长度,而是字符的显示宽度,在字段类型为int时,无论你显示宽度设置为多少,int类型能存储的最大值和最小值永远都是固定的,这里贴一些原文片段。
The number in the parenthesis does not determines the max and min values that can be stored in the integer field. The max and min values that can be stored are always fixed. The display width of the column does not affects the maximum value that can be stored in that column. A column with INT(5) or INT(11) can store the same maximum values. Also, if you have a column INT(20) that does not means that you will be able to store 20 digit values (BIGINT values). The column still will store only till the max values of INT.
那么照文中所说,所以无论怎么设置int类型的显示宽度,int所能存储的最大值和最小值是固定的,那么这个显示宽度到底有什么用呢?
当int字段类型设置为无符号且填充零(UNSIGNED ZEROFILL)时,当数值位数未达到设置的显示宽度时,会在数值前面补充零直到满足设定的显示宽度,为什么会有无符号的限制呢,是因为ZEROFILL属性会隐式地将数值转为无符号型,因此不能存储负的数值。
具体用以下代码解释。
首先创建一张表:
CREATE TABLE int_demo (
id INT(11) NOT NULL AUTO_INCREMENT,
a INT(11) NOT NULL,
b INT(11) UNSIGNED ZEROFILL NOT NULL,
c INT(5) DEFAULT NULL,
d INT(5) UNSIGNED ZEROFILL NOT NULL,
e INT(15) DEFAULT NULL,
PRIMARY KEY (`id`)
)插入两条数据
INSERT INTO int_demo (a, b, c, d, e) VALUES (1, 1, 1, 1, 1);
INSERT INTO int_demo (a, b, c, d, e) VALUES (1234567890, 1234567890, 1234567890, 1234567890, 1234567890);select * from int_demo;
| id | a | b | c | d | e |
|---|---|---|---|---|---|
| 1 | 1 | 00000000001 | 1 | 00001 | 1 |
| 2 | 1234567890 | 01234567890 | 1234567890 | 1234567890 | 1234567890 |
结论
从上个例子我们可以得出以下几个结论:
- 如果一个字段设置了无符号和填充零属性,那么无论这个字段存储什么数值,数值的长度都会与设置的显示宽度一致,如上述例子中的字段b,插入数值1显示为00000000001,左边补了10个零直至长度达到11位;
- 设置字段的显示宽度并不限制字段存储值的范围,比如字段d设置为int(5),但是仍然可以存储1234567890这个10位数字;
- 设置的字符宽度只对数值长度不满足宽度时有效,如d字段int(5),插入1时,长度不足5,因此在左边补充4个零直到5位,但是插入1234567890时超过了5位,这时的显示宽度就起不了作用了。
如果是VARCHAR
咱们假设是utf-8格式
a)假如存4个汉字,则占用43=12字节。
b)存4个字母,则占用41=4字节。
c)varchar会用一个或两个字节保存长度。即varchar(20)和varchar(255)对应的索引长度分别为203(utf-8)(+2+1),2553(utf-8)(+2+1),其中"+2"用来存储长度信息,“+1”用来标记是否为空,加载索引信息时用varchar(255)类型会占用更多的内存; (备注:当字段定义为非空的时候,是否为空的标记将不占用字节)
d)硬盘上,varchar(100)和varchar(200)存储一个相同的字符串,实际是一样的,根据字符长度分配存储空间。但mysql在内存保存时,是使用固定大小的内存块保存值,就是使用字符类型中定义的长度,varchar(200)即200个字符空间。显然,这对于排序或者临时表(这些内容都需要通过内存来实现)作业会产生比较大的不利影响。
如果是CHAR
a)从碎片角度进行考虑,使用CHAR字符型时,由于存储空间都是一次性分配的。为此某个字段的内容,其都是存储在一起的。单从这个角度来讲,其不存在碎片的困扰。而可变长度的字符数据类型,其存储的长度是可变的。当其更改前后数据长度不一致时,就不可避免的会出现碎片的问题。故使用可变长度的字符型数据时,数据库管理员要时不时的对碎片进行整理。如执行数据库导出导入作业,来消除碎片。
b)考虑其长度的是否相近,如果某个字段其长度虽然比较长,但是其长度总是近似的,如一般在90个到100个字符之间,甚至是相同的长度。此时比较适合采用CHAR字符类型。比较典型的应用就是MD5哈希值。当利用MD5哈希值来存储用户密码时,就非常使用采用CHAR字符类型。因为其长度是相同的。另外,像用来存储用户的身份证号码等等,一般也建议使用CHAR类型的数据。
另外请大家考虑一个问题,CHAR(1)与VARCHAR(1)两这个定义,会有什么区别呢?虽然这两个都只能够用来保存单个的字符,但是VARCHAR要比CHAR多占用一个存储位置。这主要是因为使用VARCHAR数据类型时,会多用1个字节用来存储长度信息。这个管理上的开销char字符类型是没有的。
varchar和char,二者在磁盘上存储占的空间是一样的。区别有二。
第一、一个变长一个固定长度。第二、在内存中的操作方式,varchar也是按照最长的方式在内存中进行操作的。比如说要进行排序的时候,varcahr(100)是按照100这个长度来进行的。
各种编码
ASCII码:一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。一个二进制数字序列,在计算机中作为一个数字单元,一般为8位二进制数,换算为十进制。最小值-128,最大值127。如一个ASCII码就是一个字节。
UTF-8编码:一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。中文标点占三个字节,英文标点占一个字节。
Unicode编码:一个英文等于两个字节,一个中文(含繁体)等于两个字节。中文标点占两个字节,英文标点占两个字节。