

复制扩展无法解决数据增长问题,这样当业务增长到某一阶段,以致上游server无法将高频访问数据全部放于内存中时,性能便会一落千丈。Nginx通过ngx_http_upstream_ip_hash_module、ngx_http_upstream_hash_module这两个模块,实现了哈希与一致性哈希算法,它们可以限制每个上游server处理的数据量,以此提升上游server的性能。我们先来看ip_hash算法。
每个IP报文头部都含有源IP地址,它标识了唯一的客户端。因此,将IP地址依据字符串哈希函数转换为32位的整数,再对server总数取模,就可以将客户端与上游server的访问关系固定下来。
它的实现非常简单,包括以下3步:
将IP地址这个字符串转化为哈希值,代码如下所示:
ngx_uint_t hash = 89;
for (i = 0; i < (ngx_uint_t) iphp->addrlen; i++) {
hash = (hash * 113 + iphp->addr[i]) % 6271;
}
接着,基于所有上游server的权重和,缩小哈希值范围:
ngx_uint_t w = hash % iphp->rrp.peers->total_weight;
最后,通过遍历所有server的权重,选取上游server:
while (w >= peer->weight) {
w -= peer->weight;
peer = peer->next;
}
可见,相对于采用二分查找的Random算法,古老的ip_hash性能有所下降(时间复杂度从O(logN)降到O(N)),在server非常多时性能不够理想。
实际上,ip_hash还有一个很糟糕的问题,就是对于IPv4地址,它会忽略最后1个字节的值。比如若IP地址为AAA.BBB.CCC.DDD,那么ip_hash只会使用AAA.BBB.CCC来求取哈希值,相关代码如下所示:
case AF_INET:
sin = (struct sockaddr_in *) r->connection->sockaddr;
iphp->addr = (u_char *) &sin->sin_addr.s_addr;
iphp->addrlen = 3;
break;
对于后出现的IPv6地址,将会使用全部16个字节的地址。为了向前兼容,ip_hash模块很难修改掉IPv4地址的这个Bug。此时,你可以使用更新的hash指令来解决,它可以对Nginx变量(也接受变量与字符串的组合)取哈希值:
upstream {
server A;
server B;
hash $remote_addr;
}
hash模块会使用CRC32函数,对变量求出32位的哈希值,之后执行与ip_hash相同的算法。
哈希算法最大的问题在于,当server数量、权重发生变化时,映射函数就会变化,很容易导致映射关系大幅变动。比如,当上游server数量为5时,关键字与上游server的映射如下所示:
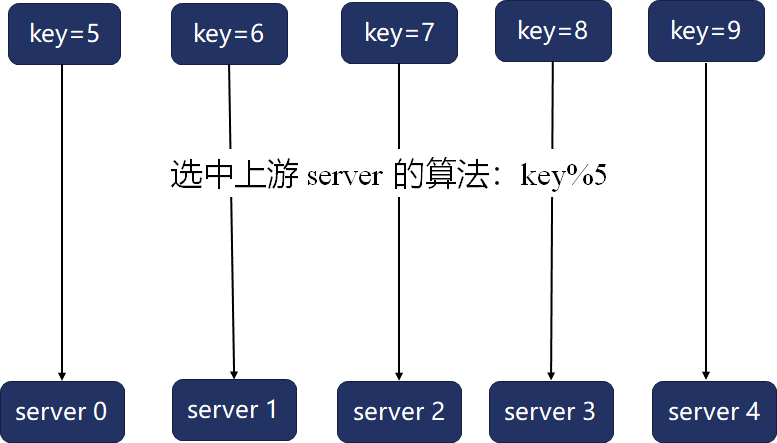
一旦server4宕机,这5个关键字的映射关系就会全部变动:

如果上游server为数据建立了缓存,那么此时会导致这5个关键字对应的缓存全部失效。
一致性哈希算法是怎样实现的?
一致性哈希算法将哈希算法中的函数映射,改为32位数字构成的环映射,大幅降低了server变动时受影响的关键字数量。如下图所示,Nginx将关键字(hash指令后的变量)基于CRC32函数转换为无符号的32位整数,其中232与0相接构成了一个环:
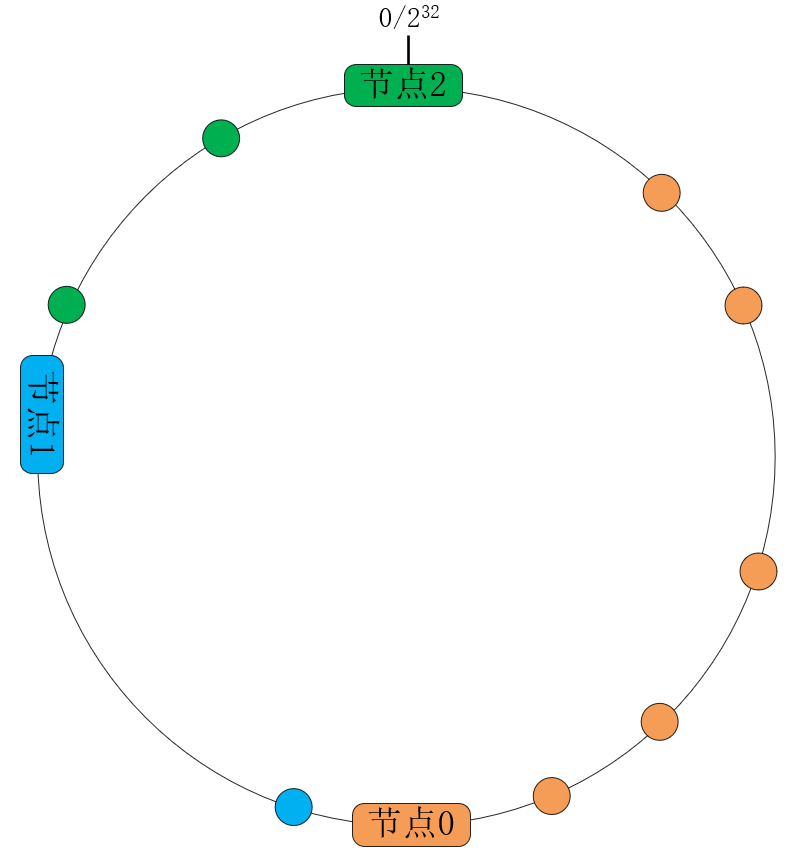
这样,3个server将会基于weight权重,各自负责环中的一段弧线,划分了处理关键字的范围。当扩容或者宕机时,只会影响相邻server节点上的关键字。
当然,这样还是有2个问题:
- 当节点1宕机时,它负责的所有请求都被映射到了节点2,这样节点2可能会抗不住压力继续宕机,进而引发雪崩效应。扩容时也一样,当增加节点3时,只是分流了节点2上的请求,这对节点0、节点1完全没有帮助。
- 如果server只是基于权重划分哈希环,那么很难保证全部关键字均衡地落进每个server上。
解决这2个问题的方案,就是在哈希环上,增加一层二次映射的虚拟节点环。这样,二次哈希既可以让数据分布更均衡,也可以由全体server共同分担宕机压力,享受扩容带来的收益。
虚拟节点数量越多,分布会越均衡。然而,在有序的哈希环上选择server,最快的方法也只是二分查找法,它的时间复杂度是O(logN),因此,虚拟节点数还是得控制在一个范围内。通常,每个真实节点对应的虚拟节点数在100到200之间,而Nginx选择为每个权重分配160个虚拟节点。
下面我们看下Nginx是如何实现一致性哈希算法的。对于哈希环上的每个虚拟节点,Nginx都会分配1个ngx_http_upstream_chash_point_t结构体表示:
typedef struct {
uint32_t hash;
ngx_str_t *server;
} ngx_http_upstream_chash_point_t;
其中,hash是二次哈希映射后的值,server则指向真实的上游服务。这些虚拟节点环会以数组的形式放在ngx_http_upstream_chash_points_t结构体中:
typedef struct {
ngx_uint_t number;
ngx_http_upstream_chash_point_t point[1];
} ngx_http_upstream_chash_points_t;
其中,number成员保存了虚拟节点的总数量,而point则是虚拟节点环的首地址。
构建虚拟节点环的初始化代码如下所示:
ngx_uint_t npoints = peer->weight * 160; //每个权重赋予160个虚拟节点
for (ngx_uint_t j = 0; j < npoints; j++) {
hash = base_hash; //基于上游server的IP、端口进行首次哈希
//基于相同的算法执行二次哈希
ngx_crc32_update(&hash, prev_hash.byte, 4);
ngx_crc32_final(hash);
//将二次哈希值放入ngx_http_upstream_chash_point_t环中
points->point[points->number].hash = hash;
points->point[points->number].server = server;
points->number++;
prev_hash.value = hash;
}
当用户请求到达时,会首先基于Nginx变量生成CRC32哈希值,接着采用二分查找法,在O(logN)时间复杂度下找到对应的真实server:
ngx_http_upstream_chash_point_t * point = &points->point[0]; //环上第1个虚拟节点
ngx_uint_t i = 0;
ngx_uint_t j = points->number;
while (i < j) { //以二分法检索虚拟节点
ngx_uint_t k = (i + j) / 2;
if (hash > point[k].hash) {
i = k + 1;
} else if (hash < point[k].hash) {
j = k;
} else {
return k; //返回哈希环中对应虚拟节点的下标
}
}
return i;
如果选出的server由于失败次数、并发连接数达到限制后,将会采用闭散列函数的方案,尝试选择相邻哈希桶上的server。另外,如果连续选出的20个server都不能使用,一致性哈希算法将会回退到RoundRobin算法。