从处理器层面上来讲,处理器保证基本的访存事务的原子性,例如当处理器读取存储器中的一个字节时,在读取过程未结束之前,其他的任何设备都不可以访问这个字节。这个保证对写入字节也成立。但是处理器自动能做的保护也就仅仅如此了。
问题描述
以下面的Go代码为例,我们对x累加了10000次,但是最终x的结果却并不为10000:
package main
import (
"fmt"
"sync"
)
func main() {
var x int
var wg sync.WaitGroup
fmt.Println("x start: ", x)
wg.Add(10000)
for i := 0; i < 10000; i++ {
go func() {
x++
wg.Done()
}()
}
wg.Wait()
fmt.Println("x end:", x)
}i++不是原子操作
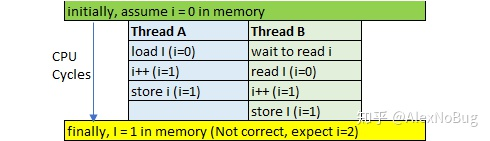
对于i++这样的操作,其实是分3步执行的,读取i的值,增加i的值,回写i的新值。这3步每一步都是原子操作,但是组合在一起就不一定是原子操作了。可以参看下图中两个线程对i的争抢示例。我们期待线程A与B中的i++可以顺序执行,最终存储器中的结果是2;但是实际上由于两个线程并行执行,结果可能得到1(当然也有可能得到2,运气好的话)。通常i++这样的操作我们称为“读-改-写”操作。
解决方法
package main
import (
"fmt"
"sync"
)
func main() {
var x int
var lock sync.Mutex
var wg sync.WaitGroup
fmt.Println("x start: ", x)
wg.Add(10000)
for i := 0; i < 10000; i++ {
go func() {
lock.Lock()
x++
lock.Unlock()
wg.Done()
}()
}
wg.Wait()
fmt.Println("x end:", x)
}
由于的确有业务逻辑要求多线程中类似于i++这样的“读-改-写”操作是原子性操作。处理器因此为软件(即程序员/编译器)提供了一种原生的总线封锁机制,即lock指令前缀。当生成的代码前有lock前缀时,例如伪代码lock i++,则整条指令在访存/修改变量/回写期间,别的设备/代码都不可以触碰被锁住的变量。从上面的例子来看就是,一旦线程A进入load i阶段,线程B就不可以再执行load i。线程B会阻塞,一直等待到线程A的store i完成,才能继续往下执行load i(此时读取到的是线程A的结果i=1),i++, store i,最后将i=2写回到内存中。